A new feature just landed on https://tabs.garden where a user is suggested similar tabs in the sidebar. This was implemented in a very simple way (spoiler: using JSON files and a rudimentary cosine-similarity score), but I was very pleased by the result.
The data at our disposal
The guitar tab data has a few things - the title, artist, when it was released, and then the tabs themselves.
title: Bless The Telephone
artist: Labi Siffre
release: 1971
key: G
capo: 5
chords: G D Em C ...
While this information is easy to parse as a human, to compute a similarity with other tabs we need to first encode this into something numerical; that is often called an "embedding".
What is an embedding?
An embedding is a numeric representation of something.
In machine learning, people often talk about text embeddings, where a sentence gets turned into a list of numbers. In this case we did something similar where each tab is turned into a sparse vector.
A sparse vector is just a map of feature names to numeric weights. For example, a song might become something like:
{
"genre:worship": 3.5,
"chord:G:maj": 0.4,
"chord:D:maj": 0.4,
"chord:E:min": 0.4,
"progression:G:maj>D:maj": 0.6,
"release-decade:2010s": 2.4,
"release-window:2010-2014": 1.8,
"key:g": 0.8
}
It is sparse because the total set of possible features is large, but any given song only has a small subset of them.
The benefit of using something like this, is that we can still easily inspect the data. If two songs are similar because of the genre, I can see that, and it also makes it easy to adjust the weights for any one property.
Cosine similarity
Once each tab is represented as a vector, we then need a way to compare them.
A very popular way to do that is using something called "cosine similarity". It measures whether two vectors point in the same direction. A score close to 1 means the vectors have a lot in common. A score close to 0 means they do not.
The formula looks something like this:
cosine_similarity(A, B) = dot(A, B) / (magnitude(A) * magnitude(B))
In the code, it's implementation with this small function:
export const cosineSimilarity = (
left: SparseVector,
right: SparseVector,
): number => {
let dot = 0;
let leftMagnitude = 0;
let rightMagnitude = 0;
Object.entries(left).forEach(([key, value]) => {
dot += value * (right[key] ?? 0);
leftMagnitude += value * value;
});
Object.values(right).forEach((value) => {
rightMagnitude += value * value;
});
if (leftMagnitude === 0 || rightMagnitude === 0) return 0;
return dot / (Math.sqrt(leftMagnitude) * Math.sqrt(rightMagnitude));
};
Building the tab vector
Taking a step back, let's dig in to how we convert our tab metadata into a tab vector. Since our data is pretty messy, first, we normalize the chord symbols:
canonicalizeChordSymbol("Dbmaj7/F"); // "C#:maj7"
canonicalizeChordSymbol("Bbmin7"); // "A#:m7"
canonicalizeChordSymbol("C/G"); // "C:maj"
canonicalizeChordSymbol("N.C."); // null
Then we define some hand-tuned weights from the various properties:
export const TAB_SIMILARITY_WEIGHTS = {
genre: 3.5,
chord: 0.8,
progression: 1.2,
metadata: 0.8,
release: 2.4,
structure: 0.3,
} as const;
I started with chord and progression features weighted higher, but that surfaced too many generic four-chord matches. After looking at the first recommendations, I shifted more weight toward genre and release era.
For chord and progression features, we had to divide by the square root of the chord count. This keeps a long tab from winning just because it has more chord events.
chords.forEach((chord) => {
addFeature(
vector,
`chord:${chord}`,
TAB_SIMILARITY_WEIGHTS.chord / Math.sqrt(uniqueChordCount),
);
});
sequence.slice(0, -1).forEach((chord, index) => {
const nextChord = sequence[index + 1];
if (!nextChord || chord === nextChord) return;
addFeature(
vector,
`progression:${chord}>${nextChord}`,
TAB_SIMILARITY_WEIGHTS.progression / Math.sqrt(totalChordCount),
);
});
Generating the most similar tabs
We read our index of tabs, build one vector per song, and then compare each song against every other song.
In pseudocode:
entries = read all songs and tabs
vectors = build one vector per song/tab
for each song:
compare against every other song with cosine similarity
sort by score descending
keep the top 3
write similarTabIds back to public/data/songs-index.json
write detailed scores to public/data/similar-tabs.json
The similarTabIds field is what the UI uses. Since the song index is already loaded by the app, rendering similar tabs does not require another request.
Rendering it
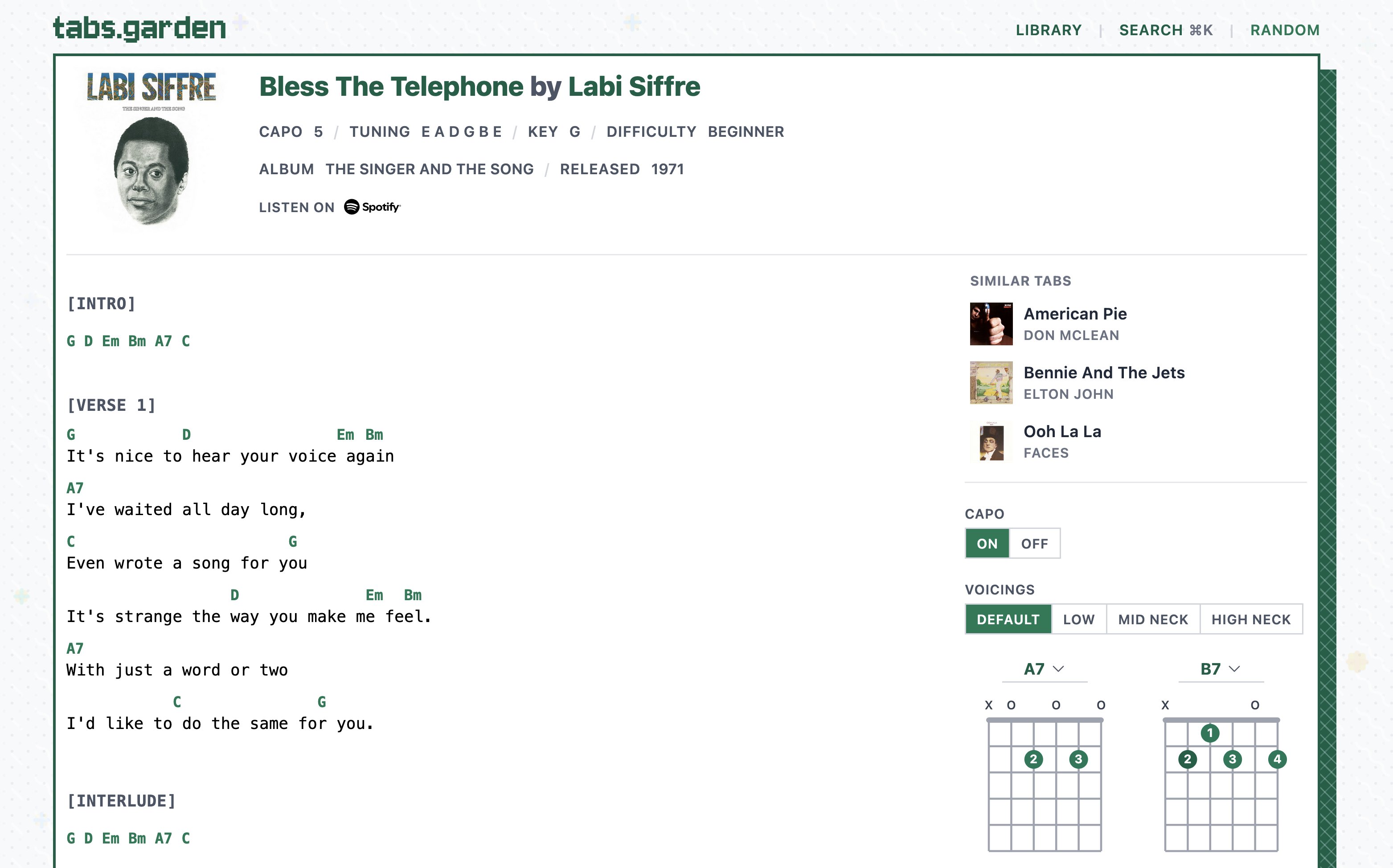
Once the IDs are embedded in songs-index.json, the UI work is straightforward. The app looks up those IDs in the existing song index and passes the resulting songs to a small presentational component.
The sidebar shows the three similar tabs above the capo, voicing, and chord controls. I also strip tab suffixes like Chords, Chord, and Chords Ver 3 from the display title so the list reads more like song names than imported tab names.
When Spotify context includes album artwork, the recommendation shows a small album image next to the title.
Future improvements
There is still a lot of improvement to be had.
Right now the weights are hand-tuned, but I could imagine running some experiments to measure the impact of each weight, and better determine what is ideal here.
Additionally, we would definitely benefit from more metadata enrichment; what we currently have is pretty limited. Many songs are missing genre data, and when genre is missing the model has to fall back to release date, chords, and tab metadata.
Better results would likely come from adding things like: instrumentation tags, tempo or energy information, richer artist information, etc.
All-in-all, this feels like a good first version. The implementation is small, and it's really easy to re-build the embeddings with no external dependencies.